

最近、AIチャットボットがずっと話題になってます。そこで私はチャットボットやQ&Aシステム、独自のエージェントに使えるAIをどうやって作ればいいのだろうと考えることが多くなりました。 Chat GPT APIのようなAPIサービスを利用するのは比較的簡単な手法だと思います。でも、私は「オープンソースの言語モデルを使って、一から自分のAIを作りたい!」と思っています。 外部の第3者がホストしているモデルを使う必要がないので、機密データを分析したいときなどにはとても良いですね。きっとワクワクするはずです。さぁ、始めましょう!
1.AIを作るためのベースモデルを選ぼう
オープンソースで提供されている言語モデルは数多くあります。その中から最適なものを選ぶことは、モデルの性能とそのサイズのバランスを保つ上で非常に重要です。先週、私はGoogle Brainの「UL2 20B」という新しいモデルを見つけました。これは、シンガポール在住のGoogle Brain シニアリサーチサイエンティストであるYi Tai氏が主導しています。これは完全にオープンで、誰でもモデルとその重みをダウンロードすることができます。 LLM(大規模言語モデル)は非商用ライセンスなど利用制限があるものが多いので、このモデルはとてもありがたいです。 技術的なことに興味がある方は、彼のブログ「A New Open Source Flan 20B with UL2」(1)を読むことを強くお勧めします。 LLMに興味のある方なら「必読」です。
2.小さな実験を行い、その結果をみてみましょう
有名な研究論文「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models(2)」を使ってみたいと思います。これには良いアブストラクトが書かれています。それは次のようなものです。実際は英文ですが、ここでは和訳しておきます。
“思考の連鎖(一連の中間推論ステップ)を生成することで、大規模言語モデルが複雑な推論を行う能力が大幅に向上することを探求する。特に、思考連鎖プロンプトと呼ばれる、いくつかの思考連鎖のデモンストレーションをプロンプトの模範として提供する簡単な方法によって、十分に大きな言語モデルにおいて、そのような推論能力が自然に出現することを示す。3つの大規模言語モデルを用いた実験により、思考連鎖プロンプトが算術、常識、記号の推論タスクのパフォーマンスを向上させることが示された。経験的な向上は顕著である。例えば、540Bパラメータの言語モデルにわずか8個の思考連鎖の模範を促すと、数学の単語問題のGSM8Kベンチマークで最先端の精度を達成し、細かく調整されたGPT-3を検証機付きで上回ることができました。”
専門用語が多いので、ちょっと読みにくいかもしれませんね。では、このアブストラクトについて2つ質問したいと思います。1つ目はこちらです。
Q : “What is the meaning of ‘a chain of thought’ in this document?
A : a series of intermediate reasoning steps
実験中の様子がわかるように、使ったnotebookを示しておきます。
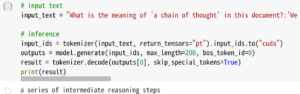
2つ目はこちらです。
Q : What is the meaning of ‘chain of thought prompting’ in this document?
A : chain of thought prompting is a method for generating a chain of thought
この2つの質問は微妙に違うのですが、モデルはどちらも混乱することなく正確に答えることができました。これは素晴らしいことです。 このモデルが本当にフリーでオープンソースなのか信じられないぐらいですね。私は、これが私たち独自のAIを作るための最高のベースモデルであることを確信しました。
このように、私たちは自分たちのAIを作るための最良のモデルを手に入れることができました。では、このモデルをどのように使いこなせば良いかを考えてみたいと思います。次回の記事で取り上げますのでお楽しみに。
(1) “A New Open Source Flan 20B with UL2” Yi Tai, Senior Research Scientist at Google Brain, Singapore, 3 , March 2023
(2) Chain-of-Thought Prompting Elicits Reasoning in Large Language Models Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou Google Research, Brain Team 10, Jan 2023
本記事は著者の意見を述べたものであり、所属する会社を代表しているものではありません。
Copyright © 2023 Toshifumi Kuga All right reserved
Notice: I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on me to correct any errors or defects in the codes and the software.
