

お待たせしました。OpenAIが誇るGPT-4に画像認識の機能が付加されました。正確には今年3月のデビューの際にデモされていた訳ですが、半年経ってやっとユーザーに開放されたということです。私も先日ChatGPT+にその機能が搭載されたので早速使ってみました。まあ、凄いの一言です!
ちなみに上記の画像もGPT-4とDALLE3の組み合わせで作りました。
さあ、実験開始です!
まずは、スマホの認識からはじめます。スマホの個数は認識できてます。この程度は楽勝ですね。

結構難しいと思ったフライト案内ですが、見事に行き先を見つけました。言語モデルとして、もともと優秀なので、意味を画像から取得するのも得意そうです。

大阪の通天閣も読めますね。ローカルな情報も問題無し。
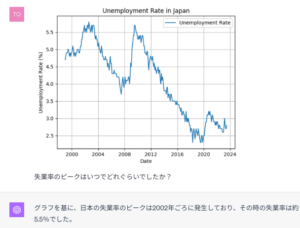
趣を変えて、分析結果の画像を入れてみました。グラフを読むのも平気です。これはすごい!

私はこれが衝撃的でした。自動車のカウントがあっさりできちゃいます。もちろん物体検知専用モデルでは無いので、誤差は常に発生します。この写真は実際48台程度かと思いますが、一般用途に使うものでしたら許容範囲でしょう。何もせずに画像を与えるだけでここまでやってしまうとは恐るべしです。

缶も数えられますが、誤差は大きめ。こういったごちゃごちゃしたものは苦手かも。


現時点では、日本語のテキストをOCR風に読み込むのは苦手。

電光掲示板の時刻も問題なく読めますね。
いかがでしたでしょうか? 特にfine-tuningなどせずに、ここまで出きてしまいました。GPT-4Vはまだ出たばかり、今後いろんなユースケースが登場しそうです。面白い事例が出たら、またこちらで紹介して行きたいと思います。Stay tuned!

Copyright © 2023 Toshifumi Kuga. All right reserved
Notice: I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on me to correct any errors or defects in the codes and the software.