

明けましておめでとうございます。本年も宜しくお願い致します。早速ですが、新しい年に相応しい、先進的なプロンプト・エンジニアリング手法がGoogle DeepMindから発表されました。” REST MEETS REACT: SELF-IMPROVEMENT FOR MULTI-STEP REASONING LLM AGENT”(1)と言う論文です。合成データ(Synthetic Data)によるファインチューニングが組み込まれており、期待できそうです!それでは始めましょう。
プロンプト全体のストラクチャー
今回のプロンプトは複雑な質問に回答するweb Q&Aシステムを念頭に置いて構成されています。構成は以下の様になっています。
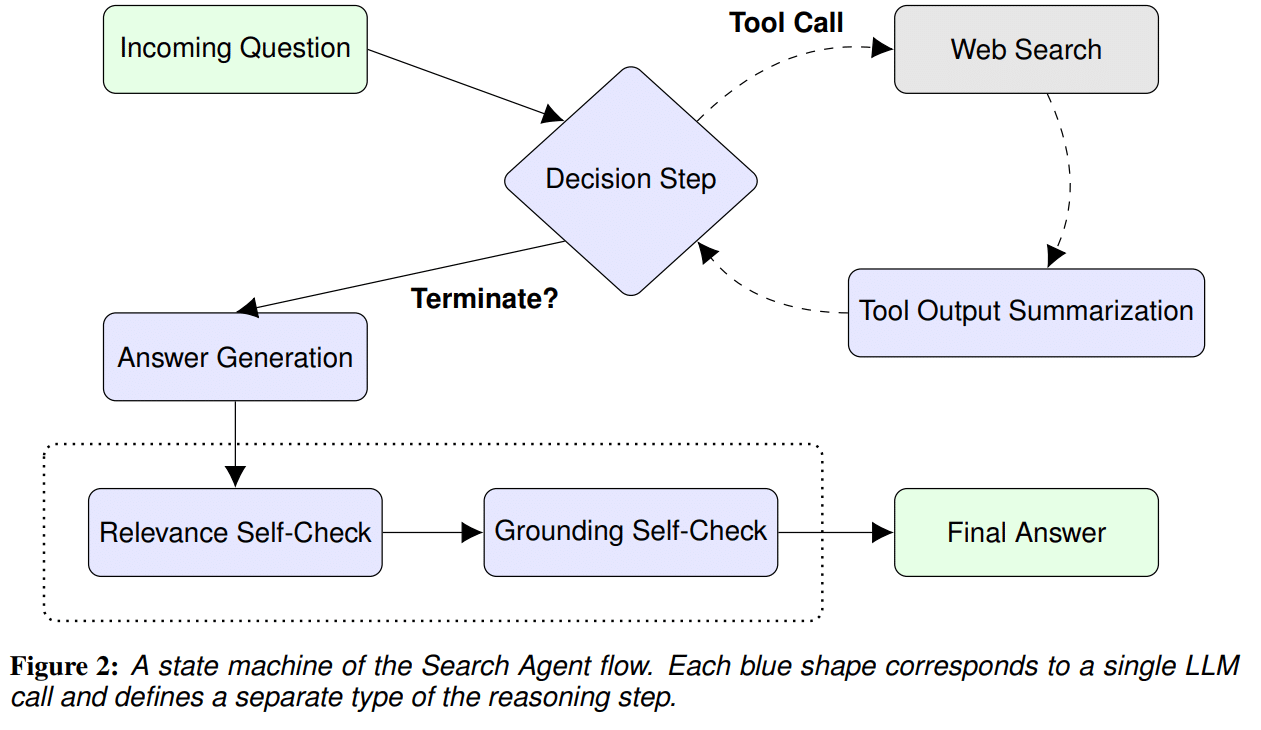
上図の青い部分がpromptで記述されるagentのフローを意味しています。web検索を使って、複雑な質問に答えることを目的としています。後半の”Relevance self-check”と”Grounding self-check”では、自分で自分の回答を確認する機能が付与されています。self-checkの機能ですね。フロー全体の詳細な説明は論文をご参照下さい。
2.「Reward model」が成功の鍵
それでは、今回の中核部分であるself-improvementの箇所を解説します。一言で言えば「新しい質の高いデータを作成し、そのデータを用いてmodelのfine-tuneを行う」ということでしょうか。この機能は以下の3つのパートから構成されます。
grow : まずSearch Agentを実行できるモデルから始めます。今回はGoogle PaLM 2-Lモデルが使用されています。このモデルを使って、選択された2000個の公開済質問のデータセットに対する推論の軌跡(trajectories)を収集します。軌跡はあまり聞き慣れない言葉かも知れませんが、推論プロセスを意味しています。強化学習ではよく使われる言葉です。
improve : 軌跡をファインチューニング用データに変換します。その際Reward modelを使用して、質の良いデータのみを選択します。labelなど外部のデータは使わないとのことです。
fine-tuning : 同じサイズの新しいモデルをこの新しいデータでファインチューニングし、元のモデルよりも性能が向上していることを確認します。
self-improvementから得られた、より良いモデルを使って上記プロセスを繰り返します。その結果、オリジナルのデータは維持したまま、新しい外部データを追加することが無くても、精度が向上するとのことです。
従ってReward modelが正確にランクを付与できるかが鍵となってきます。Reward modelはこの論文ではpromptで構築されています。せっかくですので、少し詳しくこのpromptを見ておきましょう。最初部分のみ表示します。
The goal of this rating is to filter out bad actions, so that they’ll be excluded from the fine-tuning dataset.
Overall, we want to the agent to produce relevant and grounded answers with minimal steps.
Anything that deviates from this goal is considered bad.If any element (thoughts, comments etc.) is empty, then it’s automatically bad.
“filter out”とありますように「基準を満たさないものはどんどん外していき、最後に残った質の高いデータのみ採用する」といった手法かと思います。詳細は論文(p19)を御覧ください。
3.合成データによる精度向上
今回の論文を含め、「Reward modelを使って、より質の高い合成データを作成し、それを用いてモデルをfine tuningすることにより精度向上を図る」論文が2023年後半にいくつかでています。2024年も引き続き精力的に研究がなされて、いろいろな成果が出てくるものと期待されます。特にLLM分野では質の高い訓練データを収集するのが徐々に困難になってきており、その解決策としても合成データによるfine-tuningが期待されています。
いかがでしたでしょうか? 合成データによるmodel精度の向上は、私たちのような膨大なデータを自力で集めることができないスタートアップにとっても大変有効な開発手段になるものと期待しています。当ブログでは、この合成データを含め、新しい技術革新をフォローして行きますので、ご期待下さい。それでは良いお年を!
1) “REST MEETS REACT: SELF-IMPROVEMENT FOR MULTI-STEP REASONING LLM AGENT” Renat Aksitov†1 , Sobhan Miryoosefi†1 , Zonglin Li†1 , Daliang Li†1 , Sheila Babayan†2 , Kavya Kopparapu†2 , Zachary Fisher1 , Ruiqi Guo1 , Sushant Prakash1 , Pranesh Srinivasan3 , Manzil Zaheer2 , Felix Yu1 , and Sanjiv Kumar1, 1Google Research, 2Google DeepMind, 3Google †Core contributors, 15 Dec 2023, https://arxiv.org/abs/2312.10003

Copyright © 2024 Toshifumi Kuga. All right reserved
Notice: I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on me to correct any errors or defects in the codes and the software.