

こんにちは、皆さんお元気でお過ごしでしょうか? 今年もあと2ヶ月を切りましたね。本当にAIの進化が凄まじかった年でしたが、まだその速度は衰えないようです。先日、新しいPrompt-engineering手法としてGoogle DeepMindより”Step-Back Prompting (1)”が発表されました。早速詳細をみてみましょう。
1.Step-Back Prompting
DeepMindからの提案なので、当初は複雑な手法かと思いましたが、コンセプトそのものはシンプルでした。ユーザーから入力された質問に対して、それに直接回答するのではなく、
・一歩引いてより一般的かつ本質的な質問を生成する (Stepback Question)
・その生成された質問に対して回答する(Stepback Answer)
・オリジナルの質問と生成した回答を基に、ユーザーへ最終回答を生成する (Final Answer)
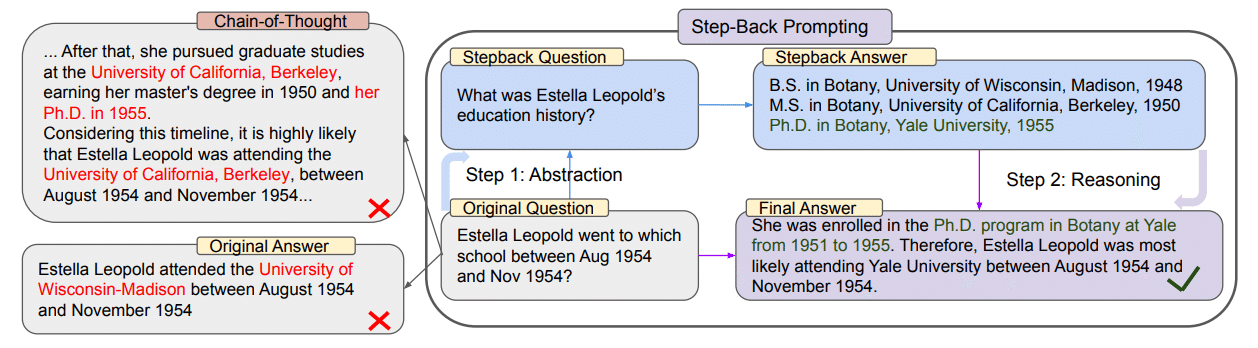
論文の概要には以下の様な記載があります。Stepback Answerを考える上でのヒントになるでしょう。
“The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise. — Edsger W. Dijkstra”
“抽象化の目的はあいまいであることではなく、絶対的に正確であることができる新しい意味レベルを作成することです。” (GPT-4による翻訳)
2.”Stepback Question” 自動生成
この手法で鍵になるのはStepback Questionをうまく作成することのようです。ただし毎回、Stepback Questionを自ら考えるのは大変かも知れません。何か良い方法はないか探していたところ、LangChainのcookbook (2) に素晴らしい自動生成手法が紹介されていました。Few shot learningを応用しているようです。

念のため、日本語訳を付けておきます。

この2つの例を先にモデルに提示しておき、新しくユーザーから「トランプが大統領のとき、ChatGPTは存在していましたか?」 の問が提示された際は、

にあります通り、「ChatGPTはいつ開発されましたか?」 と、より一般的な質問が生成できています。これを使って最終回答を導けば、高い精度が得られるということです。このcookbookでは正解が導かれてました。私が試したところでは常に100%正しい訳ではないですが、精度は確かに高そうでした。論文によると以下のようにGPT-4を超える精度も達成しているようです。
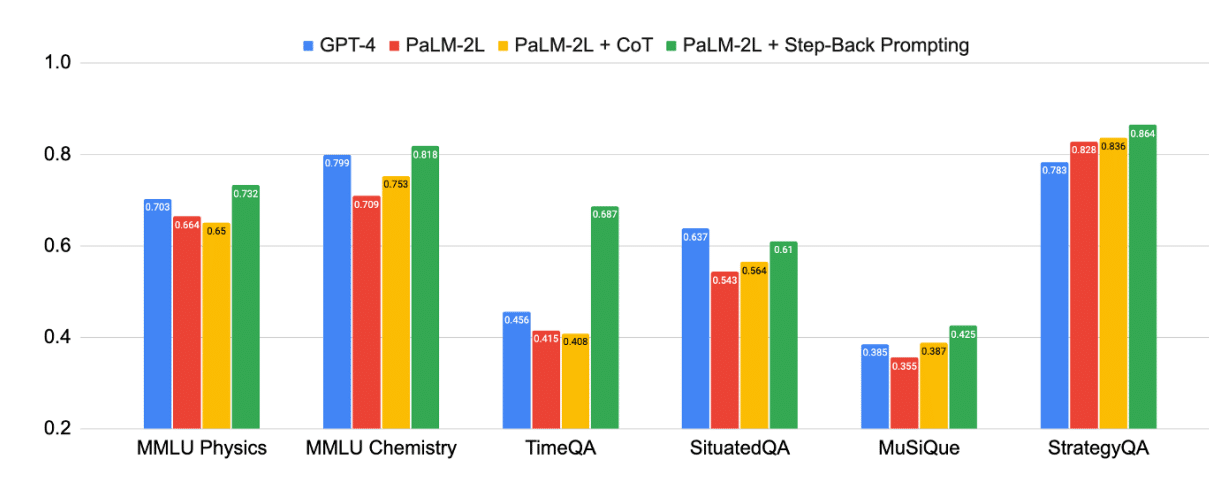
3.今後の発展への期待
“Step-Back Prompting”はシンプルな構造なので、いろいろと応用が効きそうです。また、CoTなど既存の手法と組み合わせても良いとのことですので、今後の発展が楽しみです。LangChainとの相性も抜群、実装も容易なので、ユースケースも増えることでしょう。
いかがでしたでしょうか? これからも、いろんな実験をやってみて成果が出たら、こちらで紹介して行きたいと思います。Stay tuned!
1) “TAKE A STEP BACK: EVOKING REASONING VIA ABSTRACTION IN LARGE LANGUAGE MODELS” Huaixiu Steven Zheng∗ Swaroop Mishra∗ Xinyun Chen Heng-Tze Cheng Ed H. Chi Quoc V Le Denny Zhou Google DeepMind” Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan, Google DeepMind, 9 Oct 2023, https://arxiv.org/abs/2310.06117
2) langchain/cookbook/stepback-qa.ipynb https://github.com/langchain-ai/langchain/blob/master/cookbook/stepback-qa.ipynb

Copyright © 2023 Toshifumi Kuga. All right reserved
Notice: I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on me to correct any errors or defects in the codes and the software.